
Computing
ATLAS-Grid-Computing
The huge amount of data taken at the ATLAS Experiment at CERN in
Geneva requires an enormous data store. This is only possible by sharing
the work over several compute centres. The LHC Experiments are combine
their forces in the so-called Worldwide LHC Computing Grid (WLCG). This
is a distributed computing infrastructure organized in 3 tiers.
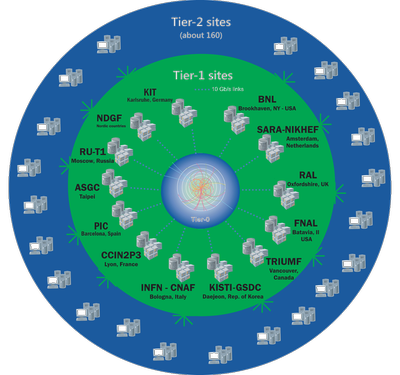
Fig. 1: WLCG is made up of four layers, or "tiers"; 0, 1, 2 and 3. Each tier provides a specific set of services. (graphic: WLCG)
The innermost layer – the tier 0 is based in the CERN data centre and
provides around 20% of the total compute capacity. The next layer is
provided by thirteen large computer centres with sufficient storage
capacity and round-the-clock support for the Grid. They fulfil the task
of safe-keeping of a proportional share of raw and reconstructed data,
as well as simulated data produced at these Tier 2s, by hosting both
huge tape and disk storage. The outermost layer – the Tier 2 centres -
are usually based at universities and research laboratories. They store
data and provide adequate computing power for analysis tasks. They
handle analysis requirements and proportional share of simulated event
production and reconstruction. Currently there are around 160 Tier 2
sites all over the world.
Since the beginning of data taking at the
LHC our group successfully operates an ATLAS-Tier-2-Centre. In order to
cope with the continuously growing data volume during data taking, we
are required to provide gradually more and more compute power as well as
disk storage over the years.
Our group is also responsible for
several ATLAS-specific operation tasks in the cloud around the Tier-1
GridKa at KIT. On a continual basis the performance of all Tier 2
centres in the cloud (data transfer, job submission, job success rate
etc.) is tested and monitored. We are responsible for summarizing, and
analysing the current status.
ATLAS HammerCloud Project
Since 2014 we are active in the ATLAS HammerCloud project.
HammerCloud (HC) is a Distributed Analysis testing system. It can test
site(s) and report the results obtained on that test. It provides a web
interface for scheduling on demand tests and reporting the results of
automated tests. A subset of the automated functional tests are used for
automated site exclusion and recovery from the central ATLAS
distributed computing workflow management system. If the dedicated tests
fail, a complete computing site is discarded from the ATLAS computing
Grid, such that no further production and/ or user analysis jobs are
brokered to an unhealthy computing site. Once the HC tests succeed
again, the compute resources of the successful site are re-included into
the computing grid.
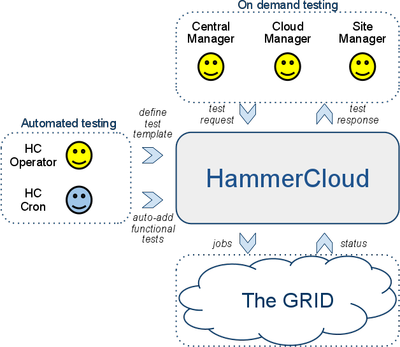
Fig. 2: Working mode of HC (graphic: HammerCloud Twiki)
Since 2019 one of the two experiment specific coordinators is from
our group. We are involved in the support of sites, maintenance tasks as
well as new developments, such as the Implementation of several
monitoring web-pages within the HammerCloud web platform, e.g. site and
cloud overviews, auto-exclusion summaries, and nightly test
visualizations. Additional features have been developed, such as
centralized benchmarking and JobShaping. The latter is a newly developed
feature for speeding up the auto-exclusion and recovery decisions by
dynamically adjust the number of parallel running jobs and providing
additional info about root causes of failing sites by submitting
automatically dedicated debug jobs to sites with failing test jobs.
R&D of innovative digital technologies
Another field of research is the development of optimizing
the usage of heterogeneous compute resources. As shown in fig.3 we are
operating a computing setup, where we integrate transparently the
resources of the HPC cluster NEMO from the Rechenzentrum
opportunistically into the local ATLAS-Tier 3 resources by connecting
the two clusters with COBalD/TARDIS.
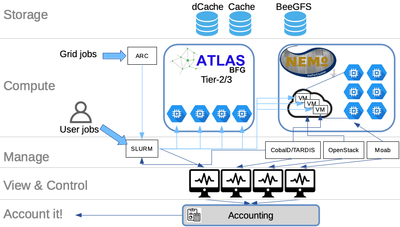
Fig.3: Transparent integration of NEMO resources into the local ATLAS Tier 2/3 center.
This allows us, to enlarge the compute resources for local ATLAS
users by a given share of the NEMO cluster, without the burden for the
user to switch between the two compute clusters and consider any
differences in terms of software or operating systems. The user submits
his/her jobs to SLURM, the batch system of the ATLAS Tier2/3 center and
uses either resources from the Tier2/3 center or virtualized nodes on
the HPC cluster.
In this context we are developing monitoring and
accounting solutions for heterogeneous site infrastructures and
validate and benchmark a possible caching infrastructure for the
LHC-Run4 storage landscape.